A Few Things I Learned About Evals
I spent most of 2024 working on capability evaluations for AI agents. This post collects some salient takeaways from that work. Although much of what I learned was thanks to my kind and talented colleagues at METR, this post represents my own views only.
To design a good eval, set the right constraints
A basic and general challenge with evaluation—one I expect is familiar to anyone who’s designed a standardized test or managed a work trial—is that an eval is not the real world, but it’s supposed to tell us something about the real world. Even with relatively flexible infrastructure, there are frequent trade-offs between practicality and validity. How do we quickly, cheaply tell if agents can manage long-running tasks on an expensive GPU cluster? What’s a controlled, reproducible way to assess how they deal with messy environments?
At a high level, a good place to start is defining a budget and other practical constraints. Then take the overarching question (e.g. “does model X pose a catastrophic risk to society?”) and keep breaking it down until the pieces can be evaluated within the constraints (e.g. “is model X competitive with humans at optimizing CUDA kernels?”). This is where things usually go wrong, so before moving forward, it’s helpful to seek critical feedback on any assumptions used to break down the question. If the intended audience—be it enterprises, academia, or regulators—isn’t buying those assumptions, look for ways to relax some constraints and address the big question more directly.
At a low level, design decisions get pretty complicated and subjective: the guidance that METR published (and several times revised) for its task bounty program is longer than this whole post. Clear constraints make the search space tractable and keep discussions focused.
Easier done than said
Intuitively, it seems like specifying a task should be easier than solving it. But if we want to be confident in the task’s quality, there’s surprisingly little truth to that. When the spec is first drafted, a task might not measure what it’s intended to measure—it might not even be possible to complete. To check for these problems, the task designer must know, in some detail, what steps an agent will take to complete the task. In practice, that often means working through the task and documenting a reference solution.
The story doesn’t end there: a task has to function beyond the path one person would take. To handle the many other paths that agents will eventually explore, the designer has to consider how they might misinterpret the instructions, get off track, and run into edge cases. Foreseeing shortcuts and loopholes is especially important as agents make increasingly sophisticated attempts to reward hack.
A task ultimately has to be specified in code, and that code will probably have bugs. The most reliable way to catch them is to have someone actually attempt the task in the agent’s environment. Automated testing helps for incremental updates to a task, but that presents its own difficulties when the agent has such a large action space. The whole development process is expensive and time-consuming, and to get enough statistical power, it has to be repeated many times.
Scaffolding is not all you need
By the time LLM agents attracted real attention, the best model (GPT-4) was clearly pretty smart. So if it fell on its face after 3 steps of a simple task, it had to be that it wasn’t really trying, or maybe it was confused by the scaffolding. This suggested low-hanging fruit to be picked by anyone with a laptop and an API key. What sort of prompt could coax the model into planning more carefully? What if it generated 10 different plans and then got to pick the best one? What if there were multiple agents working together? So many possibilities! Evaluators worried about missing latent capabilities that could be unlocked with a simple change to the prompts or scaffolding.
That concern wasn’t entirely unfounded, but all in all, I’ve found scaffolding progress underwhelming compared to earlier expectations. It bears an interesting resemblance to Moravec’s paradox and the failures of symbolic AI: agency isn’t one skill, much less one that can be instilled with a simple prompt like “plan carefully before you act”. Yet it comes so naturally to humans that we can forget it’s a skill at all. With such impressive chatbots, it was easy to anthropomorphize: surely if this model can write like a human, it can plan like one too?
Nope. The skills weren’t there. A bit of extra logic wasn’t going to produce them for all the usual reasons that a bit of extra logic doesn’t produce intelligent behavior. Elaborate systems to shuffle prompts and generations around just obfuscated what was happening and confused the models.
To be sure, scaffolding can have an impact on performance. It’s been most pronounced with models like o1-preview that can come up with good plans but haven’t been trained to act on them. As model developers direct more attention to agents as a use case, I expect that situation to become increasingly rare. Often, the latest model with simple scaffolding will beat its predecessor with the most sophisticated scaffolding.
The Bitter Lesson strikes again… with a caveat
Progress in machine learning often comes from finding stupid ways to throw compute at a problem and realizing that they actually work. Here’s one of the most striking graphs I saw last year:
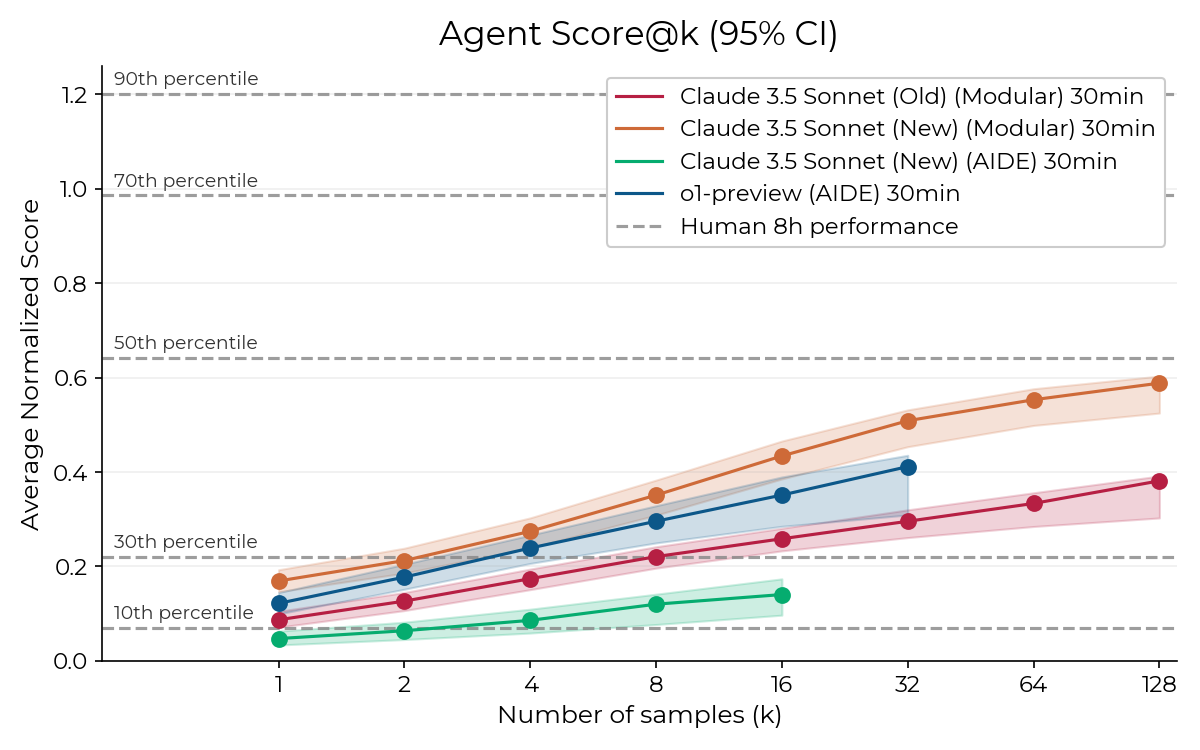
From the RE-Bench paper
RE-Bench tasks are challenging, and agents usually failed pretty badly, but every now and then they did alright. That suggested a very straightforward way to improve performance: retry the same task many times and pick the best solution. It turned out that for easily automatically verifiable tasks, best-of-k is a solid way to turn higher compute budgets into higher success rates.
The caveat is that most tasks are not easily automatically verifiable. Some things, like code quality, are just subjective. But even objective criteria may require an “answer key” to check against—and if we had that, why would we need an AI to complete the task? For tasks that are automatically verifiable, like GPU kernel optimization, the verifier needs to be quite robust. That’s because best-of-k amplifies false positives just as much as true positives: setting k = 100 is giving the agent 100 opportunities to find a bug in the verifier.
At some point language models will get good at checking their work, and with best-of-k, they’ll be good at many other things. This might happen in the next couple of years, but the highest levels of reliability could take longer—just look at how long it took for autonomous vehicles. Until then, the need for manual verification will limit many real-world applications.
Good proxies are hard to come by
Whether a model succeeds at a task is, at most, one bit of information. To build a complete picture of model capabilities—which are reliable, which are emerging, and which are far away—we have to do many runs of many tasks, which gets expensive in terms of development time as well as API costs. But in principle each run contains far more than one bit of information: the model is generating a probability distribution over tens of thousands of tokens that might come next, and doing so hundreds of times per minute. It would be great if we could use this information to estimate an agent’s chances of success with fewer runs.
Unfortunately, such an estimate would rely on certain assumptions about the relationship between text prediction and task completion, and those assumptions break pretty easily.
For example: maybe if a model is less surprised by a correct solution to the task (that is, the model assigns a solution higher log likelihood), it’s closer to generating a correct solution itself. I investigated the naive version of this, as well as some “improved” versions, but they didn’t produce clearer trends than, say, model size and task duration. To the proxy measure, it’s more important that a model assigned 1% probability to a word choice than that it assigned 10% probability to correctly identifying a bug.
It should be possible to get better estimates by actually running the agent. Maybe if we run it with human assistance, the amount of assistance needed will indicate how close the agent is to completing the task independently. That’s the idea behind the expert best-of-N method, which produces estimates like…
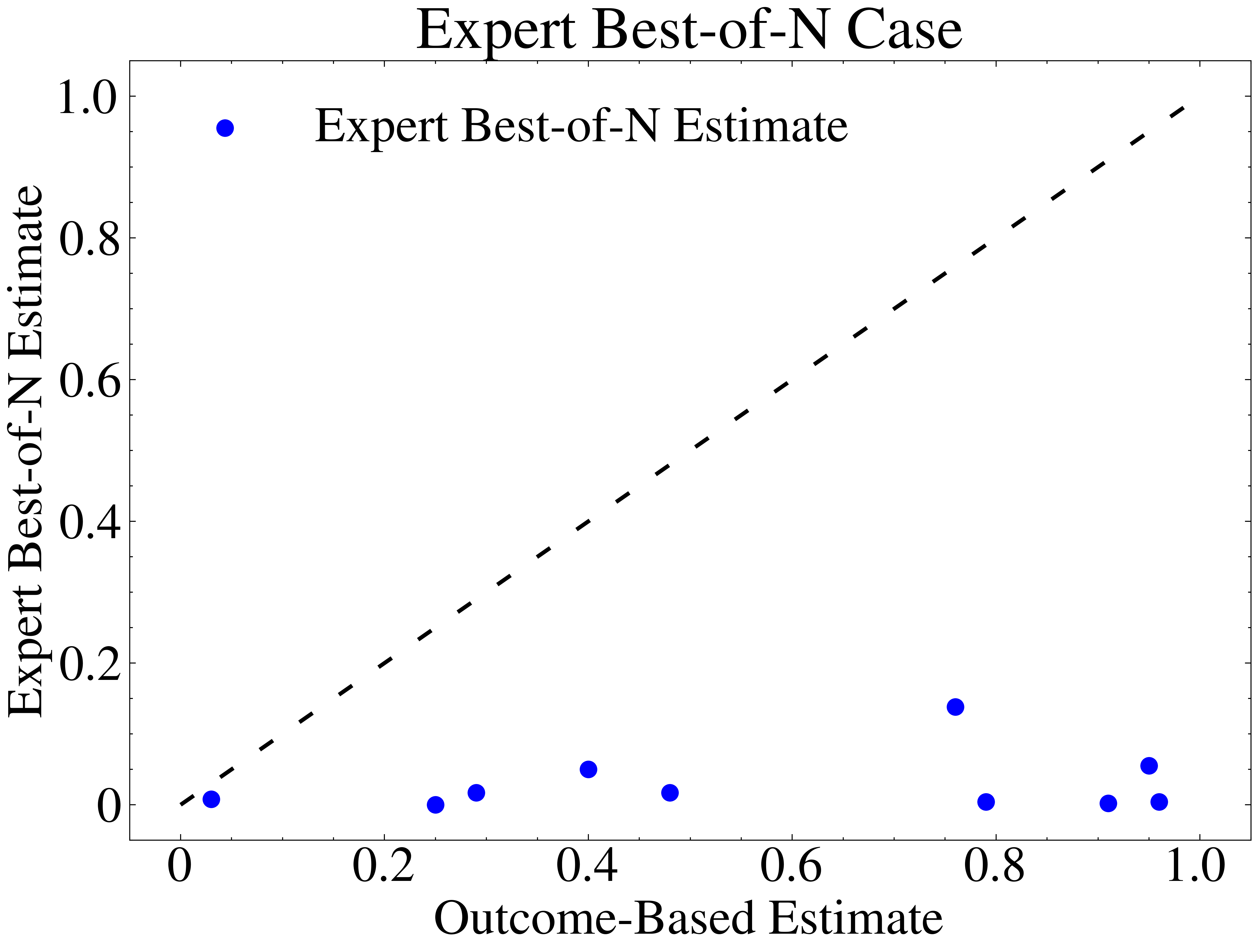
From Højmark et al., Analyzing Probabilistic Methods for Evaluating Agent Capabilities
As the authors discuss, it’s probably possible to improve upon this method. But so far nothing like it has become reliable and widely accepted. The fundamental problem is that some facts about generated text don’t matter for the outcome of the task, and some matter a great deal; unless we very accurately model that relationship, noise overwhelms the signal. And the most accurate, general “model” is—you guessed it—running the actual task.